
“Esta es una publicación de blog muy subjetiva. No te enfades si no estás de acuerdo. ¡Estás advertido!”
Si eres un desarrollador de cualquier tipo, es probable que hayas oído el término “Serverless” y sepas lo que significa. Por eso no voy a explicar qué es la arquitectura serverless, sino que voy a hablar sobre algunas herramientas que puedes usar para empezar con serverless y crear APIs listas para producción.
Recursos
- NodeJS
- ExpressJS
- SequelizeJS
- AWS RDS
- Funciones de AWS Lambda
- AWS CloudFormation
- AWS API Gateway
El recurso más importante aquí es “Serverless Framework”, pero más sobre eso en la próxima sección. Esta es una publicación de blog muy subjetiva.
Básicamente, la elección se reduce a tres cosas: lenguaje, base de datos y proveedor de servicios en la nube. Mi elección es NodeJS (ExpressJS) con una base de datos MySQL alojada en funciones de AWS Lambda. Pero puedes hacer cualquier cosa, como:
- Python con PostgreSQL alojado en Azure.
- C# con MSSQL en Google Cloud Platform
Lo mejor de esta infraestructura es que puedes combinar diferentes tecnologías, servicios y/o plataformas, con cambios mínimos en cómo se crea, administra y despliega el código.
¿Por qué Serverless Framework?
Serverless Framework es una caja de herramientas de código abierto que permite a los desarrolladores crear, empaquetar y desplegar su base de código en cualquier plataforma en la nube, en cualquier lenguaje.
Ahora, es fácil confundirse entre Arquitectura Serverless y Framework. Bueno, espero que ya sepas sobre la arquitectura serverless y lo que aporta, p. ej.
- Sin gestión de servidores.
- Escalabilidad infinita
- Pago según el uso
- Alta disponibilidad
¡Pero entonces, ¿qué demonios hace el Serverless Framework?!?! 🤔🤔🤔
- Solución para todos los casos: El framework se encarga de todas las configuraciones necesarias, independientemente del lenguaje o proveedor de servicios en la nube que uses, lo que hace que tu código sea reutilizable.
- Enfoque en el desarrollo: El framework te permite enfocarte únicamente en la lógica de tu negocio. Se encarga de configurar las diversas aplicaciones necesarias para crear una API completa.
- Código como infraestructura: El framework proporciona un único archivo (serverless.yml) que permite a los desarrolladores definir y crear aplicaciones enteras con un solo comando.
En nuestro caso particular, serverless gestiona los siguientes recursos;
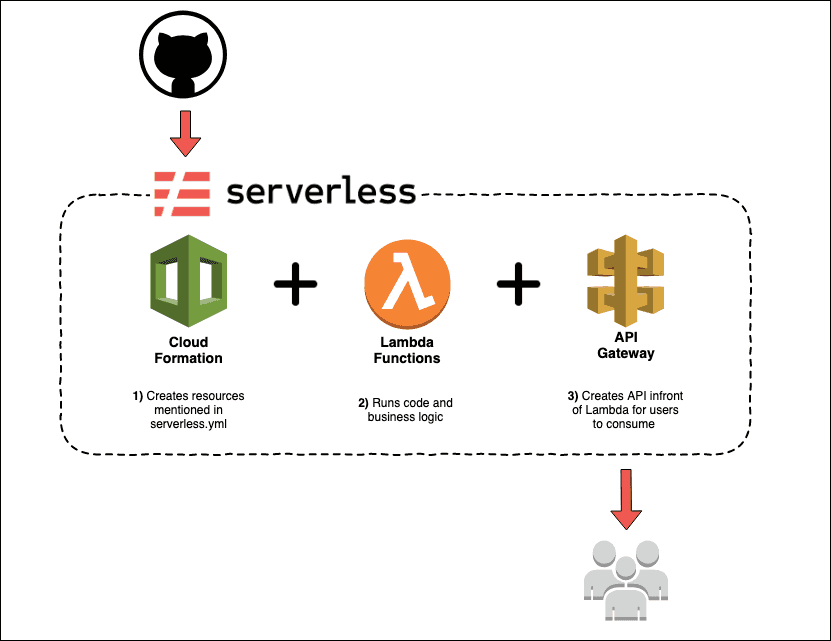
Paso 1
Serverless utiliza “AWS CloudFormation” para crear un conjunto de todos los recursos que necesitamos. Podemos usar la interfaz de línea de comandos de serverless para crear y desplegar estos recursos con:
serverless deployPaso 2
La pila consiste en funciones Lambda que ejecutan nuestro código. Las funciones Lambda son basadas en eventos, lo que significa que pueden ser activadas con una solicitud HTTP, lo cual es ideal ya que estamos creando una API.
Paso 3
La pila también crea un API Gateway, el cual está vinculado con nuestras funciones Lambda. API Gateway proporciona un punto de conexión configurado con SSL al que pueden acceder los usuarios. También maneja el almacenamiento en caché por sí mismo.
Creo que captas la idea. ¡Pongamos manos a la obra con algo de código real! 😄😄😄
Vamos a programar
Antes de comenzar, necesitarás una cuenta de AWS, aunque sea en el nivel gratuito.
La aplicación que estamos construyendo es solo para fines de demostración. Tiene tres entidades, a saber: Usuario, Publicaciones y Comentarios. Creo que todos tendrán bastante claro el propósito de cada entidad y sus relaciones entre sí. Puedes encontrar el repositorio de código aquí.
- Lo primero que necesitas hacer es instalar serverless-cli con
npm install -g serverless- Entonces tendrás que configurar serverless con AWS. Puedes ver los detalles aquí.
serverless config credentials --provider aws --key AWS_ACCESS_KEY --secret AWS_SECRET_KEY- Crea un nuevo proyecto serverless
serverless create --template aws-nodejs --path PROJECT_NAME- template → Se utiliza para definir qué proveedor y lenguaje deseas elegir. Hay varias plantillas pre-creadas. Puedes verlas en serverless.com
- path → establece el nombre del proyecto/servicio
- Luego simplemente ingresa al directorio de tu proyecto y configura npm.
cd PROJECT_NAME && npm init -y- Instala las dependencias del proyecto.
npm install express body-parser sequelize mysql2 dotenv serverless-http2npm install —save-dev serverless-offline serverless-dotenv-pluginNo te contaré sobre todas las dependencias, solo las relacionadas con serverless, es posible que no estés familiarizado con ellas;
- serverless-http → Básicamente, un envoltorio alrededor de tu API (construida con Express, Hapi, Koa, etc.).
- serverless-offline → Permite desarrollar y probar código en tu máquina local.
- serverless-dotenv-plugin → Nos permite usar archivos .env para definir variables de entorno
serverless.yml
En este punto debería existir un archivo llamado “serverless.yml”. Declararás todos los recursos que quieras utilizar en tu aplicación dentro de este archivo. El framework Serverless se encargará de crear y desplegar esos servicios utilizando AWS CloudFormation por sí mismo.
Después de eliminar los comentarios del archivo, cámbialo al siguiente formato
service: serverless-node
provider:
name: aws
runtime: nodejs8.10
stage: dev
region: eu-west-1
functions:
user:
handler: functions/user.index
events:
- http:
path: /user
method: ANY
cors: true
- http:
path: /user/{proxy+}
method: ANY
cors: true
post:
handler: functions/post.index
events:
- http:
path: /post
method: ANY
cors: true
- http:
path: /post/{proxy+}
method: ANY
cors: true
comment:
handler: functions/comment.index
events:
- http:
path: /comment
method: ANY
cors: true
- http:
path: /comment/{proxy+}
method: ANY
cors: true
plugins:
- serverless-offline
- serverless-dotenv-pluginDesglosemos este archivo
- service → nombre de tu proyecto
- provider → contiene algunas configuraciones generales para todo el proyecto
- functions → contenedores donde vivirá tu API
- plugins → paquetes npm para serverless
Ampliaré más sobre “functions”
- api → nombre de la funcion lambda
- handler → punto de entrada de la función lambda Se declara como archivo.función
- events → las funciones Lambda pueden ser activadas por diferentes tipos de eventos; estamos utilizando solicitudes HTTP
- path → un recurso proxy con una variable de ruta voraz {proxy+}
- method → todos los tipos de métodos
- cors → activa CORS
En este momento, tenemos tres funciones lambda que pueden ser activadas en cualquier ruta que coincida con los valores de “path” para todos los métodos HTTP. Esto es perfecto para nuestro escenario porque queremos que ExpressJS maneje el enrutamiento en lugar de API Gateway.
app.js
Ahora, como con cualquier proyecto NodeJS, lo primero que necesitamos hacer es crear un servidor. Sabemos que “nombre_de_la_función.index” es el punto de entrada a nuestras funciones, así que aquí es donde inicializaremos el framework Express y manejaremos el enrutamiento.
const express = require("express")
const bodyParser = require("body-parser")
const serverless = require("serverless-http")
const app = express()
/* Body Parser */
app.use(bodyParser.json())
app.use(bodyParser.urlencoded({ extended: false }))
/*
* ==================
* API Routes Go Here
* ==================
*/
module.exports.index = serverless(app)En nuestro caso, tenemos tres funciones, a saber: usuario, comentario, publicación, una para cada entidad. Utilizaremos el mismo diseño de archivo para crear tres funciones lambda, como está definido en serverless.yml.
Nota: El nombre de los archivos (que contienen las funciones lambda) y los métodos exportados deben ser exactamente iguales a los definidos en serverless.yml.
Conexiones a la base de datos
Uno de los principales problemas que enfrenté fue reutilizar la conexión a la base de datos. Inicialmente, cada vez que llamaba a un endpoint, se creaba una nueva conexión a la base de datos. Tenía que cerrar manualmente las conexiones al final de cada función.
Esto significa que nuestras conexiones a la base de datos aumentarán de forma lineal y agregarán una carga innecesaria al crear una nueva conexión cada vez 😥😥😥
¿¿Por qué pasa esto??
Las funciones Lambda son, por naturaleza, sin estado y no tienen afinidad con la infraestructura subyacente. ¡¡Esto las hace infinitamente escalables, lo cual es genial!! pero también nos introduce un gran problema 😦😦😦
Para entender por qué sucede esto, veamos el ciclo de vida de una función Lambda:
- Descargar tu código
- Empezar un nuevo contenedor
- Inicializar tiempo de ejecución
- Ejecutar tu código
- Reclamar contenedor
Ahora, cada vez que se ejecuta tu código, se crea un nuevo contenedor que no tiene el contexto de la ejecución anterior, por lo que no podemos reutilizar las conexiones a la base de datos.
Todavía hay esperanza 😌
AWS mantiene el contenedor en ejecución durante un máximo de 15 minutos después de la ejecución del código, por lo que las solicitudes subsiguientes se ejecutan en el mismo contenedor y la conexión a la base de datos se puede reutilizar.
Sin embargo, la documentación de AWS señala claramente que no hay certeza de que esto siempre sea así.
dbCon.js
const Sequelize = require("sequelize")
const sequelize = new Sequelize(
process.env.DB_NAME,
process.env.DB_USERNAME,
process.env.DB_PASSWORD,
{
host: process.env.DB_HOST,
port: process.env.DB_PORT,
dialect: process.env.DB_DIALECT,
}
)
// Models
const User = require("./models/User")(sequelize, Sequelize)
const Post = require("./models/Post")(sequelize, Sequelize)
const Comment = require("./models/Comment")(sequelize, Sequelize)
/* The magic lies here */
let connection = {}
let Models = {
User,
Post,
Comment,
}
/**
* Creating Associations
*/
Object.keys(Models).forEach(function (modelName) {
if (Models[modelName].associate) {
Models[modelName].associate(Models)
}
})
module.exports = async () => {
if (connection.isConnected) {
console.log("use existing connection")
return Models
}
try {
await sequelize.sync()
await sequelize.authenticate()
connection.isConnected = true
console.log("use new connection")
return Models
} catch (error) {
console.log(`Connection Error: ${error}`)
}
}Las funciones Lambda congelan su estado durante un máximo de 15 minutos después de la ejecución del código. Durante este tiempo, cualquier cosa declarada “fuera” de la función misma se mantiene.
El contenedor mantiene el estado del objeto de “conexión” y la conexión de Sequelize porque están definidos fuera de la función lambda. Ahora, cada vez que se reutiliza el contenedor, simplemente usamos una condición – if – para verificar si existe una conexión a la base de datos o si necesitamos crear una nueva.
Probé un par de enfoques diferentes, sin obtener resultados satisfactorios. Luego encontré el enfoque anterior en la publicación del blog de Adnan Rahić’s blog post.
Despliega tu código
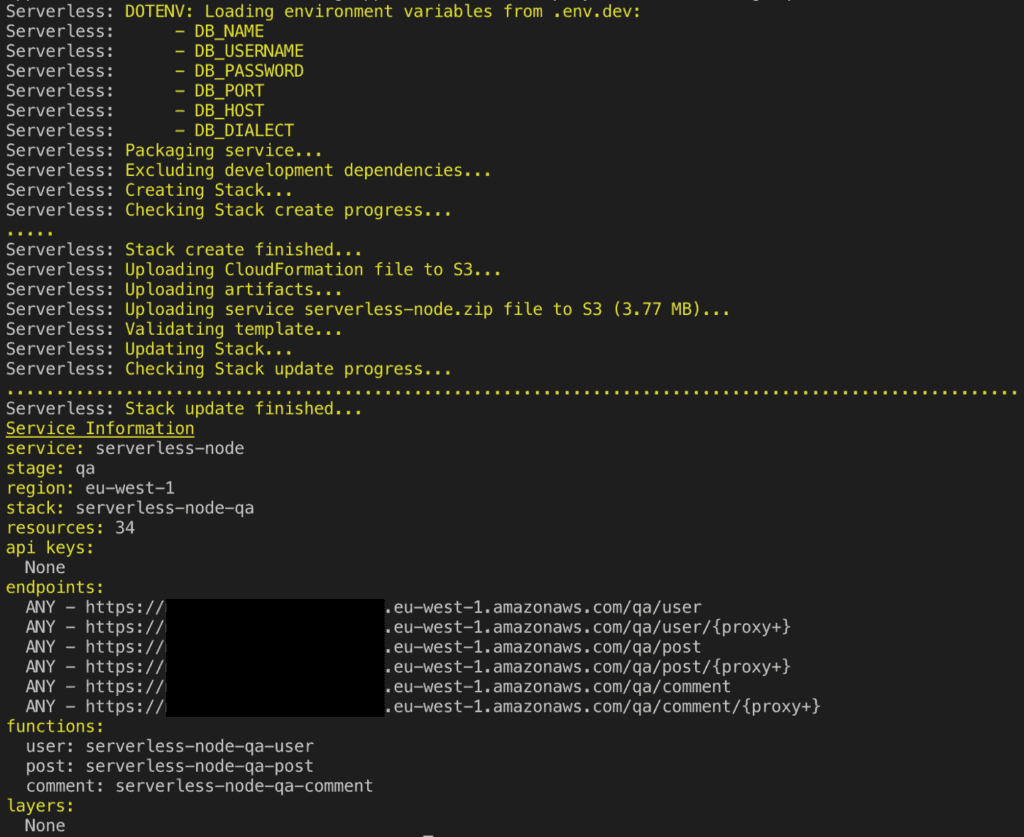
El framework Serverless hace que el despliegue sea muy sencillo. Si tienes todo lo demás configurado, simplemente ejecuta el siguiente comando
serverless deploy --env dev --stage qa- –env → habilitar el uso de variables de entorno específicas solamente
- –-stage → habilita el despliegue solo en un entorno específico
Elimina tu código
serverless removeEl comando anterior elimina todos los recursos de AWS utilizados en tu aplicación. Añadir “–stage” eliminará solo el escenario específico de API Gateway y los recursos relacionados.
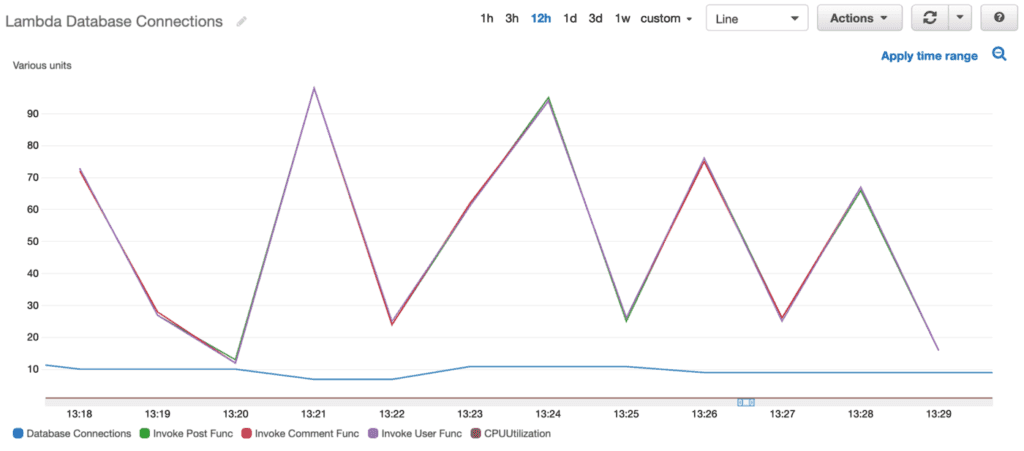
Resultados
A continuación se muestran las métricas tal como las muestra CloudWatch en la consola de AWS, después de invocar cada lambda 500 veces a través de Postman.
Este es mi enfoque para configurar una API lista para producción utilizando el framework Serverless. Una vez más, puedes utilizar cualquier lenguaje que prefieras con cualquier base de datos. Con ligeras modificaciones, incluso puedes usar MongoDB.
Existen otras alternativas como DynamoDB y AWS Aurora Serverless, que están diseñadas teniendo en cuenta la arquitectura serverless.
“Creo que estas son las mejores herramientas disponibles en este momento, si alguien quiere adentrarse en el mundo serverless.”