
“This is a highly opinionated blog post. Don’t catch on fire if you don’t agree. You have been Warned!”
If you’re a developer of any sort, chances are you’ve heard of the term “Serverless” and know what it means. That’s why I’m not going to explain what serverless architecture is, rather I’m going to talk about some tools you can use to get started with serverless and create production ready APIs.
Resources
- NodeJS
- ExpressJS
- SequelizeJS
- AWS RDS
- AWS Lambda Functions
- AWS CloudFormation
- AWS API Gateway
The most important resource here is “Serverless Framework”, but more about that in the next sectionThis is a highly opinionated blog post.
So basically the choice boils down to three things; language, database and cloud service provider. My choice of poison is NodeJS (ExpressJS) with a MySQL Database hosted on AWS Lambda Functions. But you can do anything like;
- Python with PostgreSQL hosted on Azure
- C# with MSSQL on Google Cloud Platform
The best thing about this infrastructure is that you can mix ’n’ match a number of technologies, services and/or platforms, with minimum change to how the code is created, managed and deployed.
Why Serverless Framework?
Serverless Framework is an open source toolbox which enables developers to create, package and deploy their codebase on any cloud platform, in any language.
Now, it’s easy to get confused between Serverless Architecture and Framework. Well, I expect that you already know about serverless architecture and what it brings to the table, i.e.
- No Server Management
- Infinite Scalability
- Pay as you Go
- High Availability
But then what the heck does Serverless Framework do ?!?! 🤔🤔🤔
- One fit all Solution: The framework takes care of all the configurations needed irrespective of which language or cloud provider you use making your code re-usable.
- Focus on Development: The framework allows you to focus only on your business logic. It takes care of setting up the various applications needed to make a full-fledge API.
- Code as Infrastructure: The framework provides a single file (serverless.yml) which enables developers to define and create entire applications with a single command.
In our particular case serverless manages the following resources;
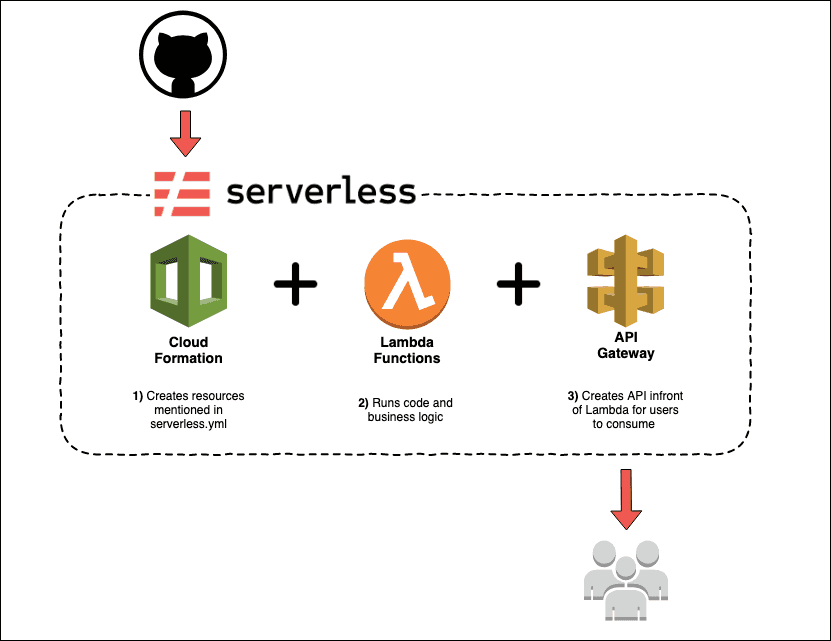
Step 1
Serverless used “AWS Cloud Formation” to create a stack of all the resources we need. We can use the serverless cli to create and deploy these resources with;
serverless deployStep 2
The stack consists of Lambda functions which run our code. Lambda functions are event based, which means they can be triggered with an HTTP request, which is ideal since we’re making an API.
Step 3
The stack also creates an API Gateway, which is linked with our Lambda functions. API Gateway provides a SSL configured endpoint which can be accessed by users. It also handles caching on it own.
I think you get the gist of it. Let’s get our hands dirty with some actual code 😄😄😄
Let’s Get Coding
Before you start, you will need an AWS account, even if its in the free tier.
The app we’re building is only for demonstration. It has three entities namely; User, Posts and Comments. I think everyone will be quite clear about the purpose of each entity and their relations among each other. You can find the code repo here.
- The first thing you need to do install serverless-cli with
npm install -g serverless- Then you’ll have to configure serverless with AWS. You can look up the details here.
serverless config credentials --provider aws --key AWS_ACCESS_KEY --secret AWS_SECRET_KEY- Create a new serverless project
serverless create --template aws-nodejs --path PROJECT_NAME- template → used to define which provider and language you want to choose. There are various templates pre-created. You can see them at serverless.com
- path → sets the project/service name
- Next just cd into your project and setup npm
cd PROJECT_NAME && npm init -y- Install project dependencies
npm install express body-parser sequelize mysql2 dotenv serverless-http2npm install —save-dev serverless-offline serverless-dotenv-pluginI won’t tell you about all the dependencies, just the ones related to serverless, you might not be familiar with;
- serverless-http → Basically a wrapper around your API (built with express, happi, Koa, etc.)
- serverless-offline → Allows developing and testing code on your local machine
- serverless-dotenv-plugin → Enables us to use .env files for defining environmental variables
serverless.yml
At this point there should be a file named “serverless.yml”. You will declare any and all resources you want to utilize in your application within this file. Serverless Framework will take care of creating and deploying those services using AWS Cloud Formation on its own.
After ridding the file of comments, change it to the template below
service: serverless-node
provider:
name: aws
runtime: nodejs8.10
stage: dev
region: eu-west-1
functions:
user:
handler: functions/user.index
events:
- http:
path: /user
method: ANY
cors: true
- http:
path: /user/{proxy+}
method: ANY
cors: true
post:
handler: functions/post.index
events:
- http:
path: /post
method: ANY
cors: true
- http:
path: /post/{proxy+}
method: ANY
cors: true
comment:
handler: functions/comment.index
events:
- http:
path: /comment
method: ANY
cors: true
- http:
path: /comment/{proxy+}
method: ANY
cors: true
plugins:
- serverless-offline
- serverless-dotenv-pluginLet’s break this file down
- service → name of your project
- provider → contains some general configurations for the whole project
- functions → containers where your API will live
- plugins → npm packages for serverless
I’ll expand further on “functions”
- api → name of the lambda function
- handler → entry point of the lambda function. Its declared as file.function
- events → Lambda functions can be triggered on different types of events we are using HTTP requests
- path → a proxy resource with a greedy path variable of {proxy+}
- method → all method types
- cors → enable CORS
Right now we have three lambda functions which can be triggered on any route matching the “path” values for all HTTP methods. This is perfect of our scenario because we want ExpressJS to handle routing rather than API Gateway.
app.js
Now as with any NodeJS project, the first thing we need to do, is create a server. We know that “function_name.index” is the entry point to our functions, so this is where we’ll initialize the express framework and handle routing.
const express = require("express")
const bodyParser = require("body-parser")
const serverless = require("serverless-http")
const app = express()
/* Body Parser */
app.use(bodyParser.json())
app.use(bodyParser.urlencoded({ extended: false }))
/*
* ==================
* API Routes Go Here
* ==================
*/
module.exports.index = serverless(app)In our case we have three functions, namely; user, comment, post one for each entity. We’ll use the same file layout to create three lambda functions, as is defined in serverless.yml.
Note: The name of the files (holding lambda functions) and the methods exported should be exactly the same as defined in serverless.yml.
Database Connections
One major issue I faced was re-using database connection. Initially each time I hit an endpoint a new database connection would be created. I had to manually close connections at the end of each function.
This means our database connections will increase linearly and add unnecessary overhead by creating new connection every time 😥😥😥
Why This Happens ??
Lambda functions are by nature stateless and have no affinity to the underlying infrastructure. This makes them infinitely scalable, which is great !! but also introduces a huge problem for us 😦😦😦
To understand why this happens lets look at a Lambda’s lifecycle;
- Download your Code
- Start a new Container
- Bootstrap the runtime
- Run your Code
- Reclaim container
Now every time your code runs, a new container is provisioned which does not have the context of the previous execution, so we can’t re-use database connections.
There is still hope 😌
AWS keeps the container running for maximum 15mins after code execution, so subsequent requests run on the same container and your database connection can be re-used.
However, AWS docs very clearly point out that there is no certainty this will always be the case.
dbCon.js
const Sequelize = require("sequelize")
const sequelize = new Sequelize(
process.env.DB_NAME,
process.env.DB_USERNAME,
process.env.DB_PASSWORD,
{
host: process.env.DB_HOST,
port: process.env.DB_PORT,
dialect: process.env.DB_DIALECT,
}
)
// Models
const User = require("./models/User")(sequelize, Sequelize)
const Post = require("./models/Post")(sequelize, Sequelize)
const Comment = require("./models/Comment")(sequelize, Sequelize)
/* The magic lies here */
let connection = {}
let Models = {
User,
Post,
Comment,
}
/**
* Creating Associations
*/
Object.keys(Models).forEach(function (modelName) {
if (Models[modelName].associate) {
Models[modelName].associate(Models)
}
})
module.exports = async () => {
if (connection.isConnected) {
console.log("use existing connection")
return Models
}
try {
await sequelize.sync()
await sequelize.authenticate()
connection.isConnected = true
console.log("use new connection")
return Models
} catch (error) {
console.log(`Connection Error: ${error}`)
}
}Lambda functions freeze their state for a max 15 mins after code execution. In this time anything declared “outside” the function itself is maintained.
The container maintains the state of the “connection” object and sequelize connection because they are defined outside the lambda function. Now, whenever the container is re-used, we simply use a conditional — if — to check whether a database connection exists or do we need to create a new one.
I tried a couple of different approaches, without getting satisfactory results. Then found the above approach in Adnan Rahić’s blog post.
Deploy your Code
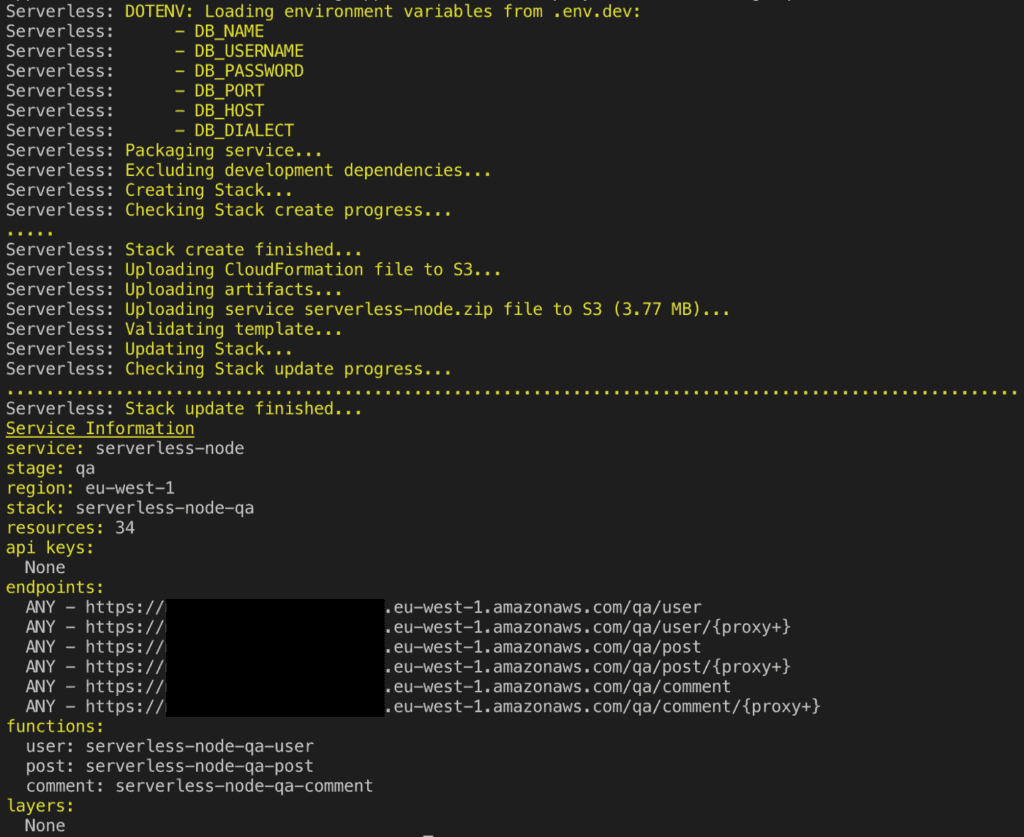
Serverless Framework makes deployment a breeze. If you’ve got everything else setup just run the following command
serverless deploy --env dev --stage qa- –env → enable using specific env variables only
- –-stage → enables deploying to specific environment only
Remove your Code
serverless removeThe above command removes all AWS resources used in your application. Adding “ — stage” will remove only the specified API Gateway stage and related resources.
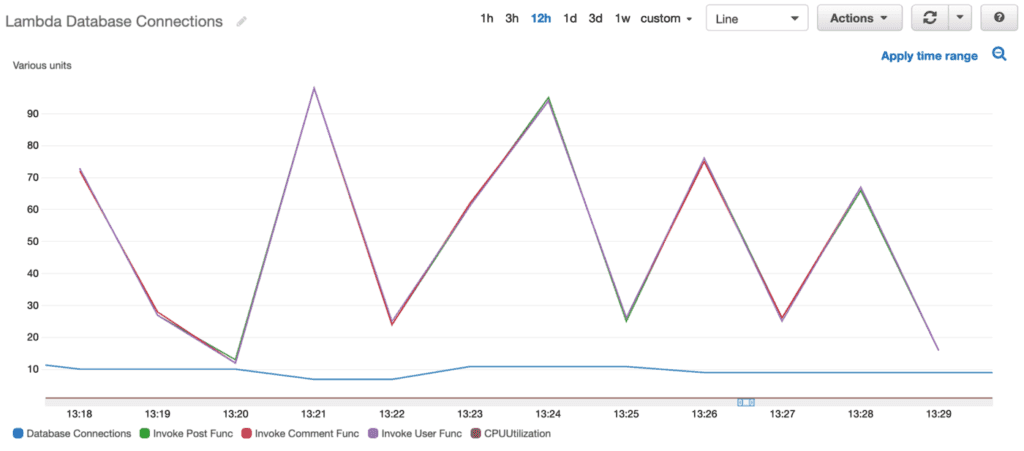
Results
Below are the metrics as shown by CloudWatch in the AWS console, after invoking each lambda 500 times via Postman.
This is my approach to setting up a production ready API using Serverless Framework. Once again you use any language you prefer with any database. With slight modifications you can even use MongoDB.
There are other alternatives like DynamoDB and AWS Aurora Serverless, which are made with serverless architecture in mind.
“I think these are the best set of tools available right now, if anyone wants to get into the serverless game.”